Running Cloud Dataflow jobs from an App Engine app
This post looks at how you can launch Cloud Dataflow pipelines from your App Engine app, in order to support MapReduce jobs and other data processing and analysis tasks.
Until recently, if you wanted to run MapReduce jobs from a Python App Engine app, you would use this MR library.
Now, Apache Beam and Cloud Dataflow have entered the picture. Apache Beam is a unified model for building data processing pipelines that handle bounded and unbounded data, as well as a collection of SDKs for building these pipelines. Google Cloud Dataflow is a managed service for executing parallelized data processing pipelines written using Apache Beam.
Dataflow allows a wide range of data processing patterns, including ETL, batch computation, and continuous computation. The Beam model supports and subsumes MapReduce. So, you can map your MR jobs to equivalent Beam pipelines, and Beam’s programming model makes it straightforward to extend and modify your existing MR logic.
The Beam Python SDK makes it easy to launch Dataflow pipeline jobs from a Python App Engine app. The SDK includes a Cloud Datastore source and sink. This makes it easy to write Dataflow pipelines that support the functionality of any existing MR jobs, as well as support additional analytics.
In this blog post, we’ll look at an example app that shows how to periodically launch a Python Dataflow pipeline from GAE, to analyze data stored in Cloud Datastore; in this case, stored tweets from Twitter. The pipeline does several sorts of analysis on the data; for example, it identifies ‘interesting’ word co-occurrences (bigrams) in the tweets, as in this snippet below.

The example is a GAE app with two services (previously, ‘modules’):
-
a GAE Standard service that periodically pulls in timeline tweets from Twitter and stores them in Datastore; and
-
a GAE Flexible service that periodically launches the Python Dataflow pipeline to analyze the tweet data in the Datastore.
The Standard service– the one that gathers the tweets– is just for example purposes; in your own apps, you probably already have other means of collecting and storing data in Datastore.
Building a service to define and launch a Dataflow pipeline from App Engine
We’ll use a Flex custom runtime based on the gcr.io/google_appengine/python image for the service that launches the dataflow pipeline, as we’ll install the gcloud sdk in the instance container(s). So, the example includes a Dockerfile used to deploy the service. As the last command in the Dockerfile, we’ll start up a Gunicorn server to serve a Flask app script (main_df.py).
The Python code for this service consists of the small Flask app script (main_df.py), which accesses a module (dfpipe) that does most of the heavy lifting in terms of defining and launching the example pipeline (in dfpipe/pipe.py).
Setting the pipeline options
As part of the process of launching a Dataflow pipeline, various options may be set.
In order to make the dfpipe module available to the Dataflow workers, the pipeline options include a setup_file flag.
pipeline_options = {
'project': PROJECT,
'staging_location': 'gs://' + BUCKET + '/staging',
'runner': 'DataflowRunner',
'setup_file': './setup.py',
'job_name': PROJECT + '-twcount',
'max_num_workers': 10,
'temp_location': 'gs://' + BUCKET + '/temp'
}
This points to a setup.py file which specifies to package the dfpipe module using setuptools. If our pipeline also had dependencies on third-party libs, we could include those in setup.py as well.
The indicated code is gathered in a package that is built as a source distribution, staged in the staging area for the workflow being run, and then installed in the workers when they start running.
A look at the Dataflow pipeline
Now let’s take a quick look at dfpipe/pipe.py, to see what the Python Dataflow pipeline does.
It reads recent tweets from the past N days from Cloud Datastore, then essentially splits into three processing branches. It finds the top N most popular words in terms of the percentage of tweets they were found in, calculates the top N most popular URLs in terms of their count, and then derives relevant word co-occurrences (bigrams) using an approximation to a tf*idf ranking metric. It writes the results to three BigQuery tables. (It would be equally straightforward to write results to Datastore instead/as well).

Using Datastore as a pipeline source
This pipeline reads from Datastore, grabbing the tweets that the other GAE Standard service is periodically grabbing and writing to the Datastore.
In main.py, the app script for the GAE standard service, you can see the Tweet entity schema:
from google.appengine.ext import ndb
class Tweet(ndb.Model):
user = ndb.StringProperty()
text = ndb.StringProperty()
created_at = ndb.DateTimeProperty()
tid = ndb.IntegerProperty()
urls = ndb.StringProperty(repeated=True)
In dfpipe/pipe.py, we can use the google.cloud.proto.datastore API to define a query for Tweet entities more recent than a given date— in this case, four days ago— by creating a property filter on the created_at field.
from google.cloud.proto.datastore.v1 import query_pb2
def make_query(kind):
"""Creates a Cloud Datastore query to retrieve all Tweet entities with a
'created_at' date > N days ago.
"""
days = 4
now = datetime.datetime.now()
earlier = now - datetime.timedelta(days=days)
query = query_pb2.Query()
query.kind.add().name = kind
datastore_helper.set_property_filter(query.filter, 'created_at',
PropertyFilter.GREATER_THAN,
earlier)
return query
Then, we use that query to define an input source for the pipeline:
p = beam.Pipeline(options=pipeline_options)
# Create a query to read entities from datastore.
query = make_query('Tweet')
# Read entities from Cloud Datastore into a PCollection.
lines = (p
| 'read from datastore' >> ReadFromDatastore(project, query, None))
...
We can use properties.get() on an element of the resulting collection to extract the value of a given field of the entity, in this case the ‘text’ field:
class WordExtractingDoFn(beam.DoFn):
"""Parse each tweet text into words, removing some 'stopwords'."""
def process(self, element):
content_value = element.properties.get('text', None)
text_line = ''
if content_value:
text_line = content_value.string_value
words = set([x.lower() for x in re.findall(r'[A-Za-z\']+', text_line)])
stopwords = [...]
return list(words - set(stopwords))
Then, this snippet from the pipeline shows how WordExtractingDoFn can be used as part of the Datastore input processing:
# Count the occurrences of each word.
percents = (lines
| 'split' >> (beam.ParDo(WordExtractingDoFn())
.with_output_types(unicode))
| 'pair_with_one' >> beam.Map(lambda x: (x, 1))
| 'group' >> beam.GroupByKey()
| 'count' >> beam.Map(lambda (word, ones): (word, sum(ones)))
Launching the Dataflow pipeline periodically using a cron job
In the example app, we want to launch a pipeline job every few hours, where each job analyzes the tweets from the past few days, providing a ‘moving window’ of analysis.
So, it makes sense to just set things up as an app cron job, which looks like this (backend is the name of the app service that handles this request, and the url is the handler that launches the job):
cron:
- description: launch dataflow pipeline
url: /launchpipeline
schedule: every 5 hours
target: backend
A pipeline job could of course be triggered by other means as well– e.g. as part of handling a client request to the app, or perhaps via a Task Queue task.
A look at the example results in BigQuery
Once our example app is up and running, it periodically runs a Dataflow job that writes the results of its analysis to BigQuery. (It would be just as easy to write results to the Datastore if that makes more sense for your workflow – or to write to multiple sources).
With BigQuery, it is easy to run some fun queries on the data. For example, we can find recent word co-occurrences that are ‘interesting’ by our metric:

Or look for emerging word pairs, that have become ‘interesting’ in the last day or so (as of early April 2017):

We can contrast the ‘interesting’ word pairs with the words that are simply the most popular within a given period (you can see that most of these words are common, but not particularly newsworthy):

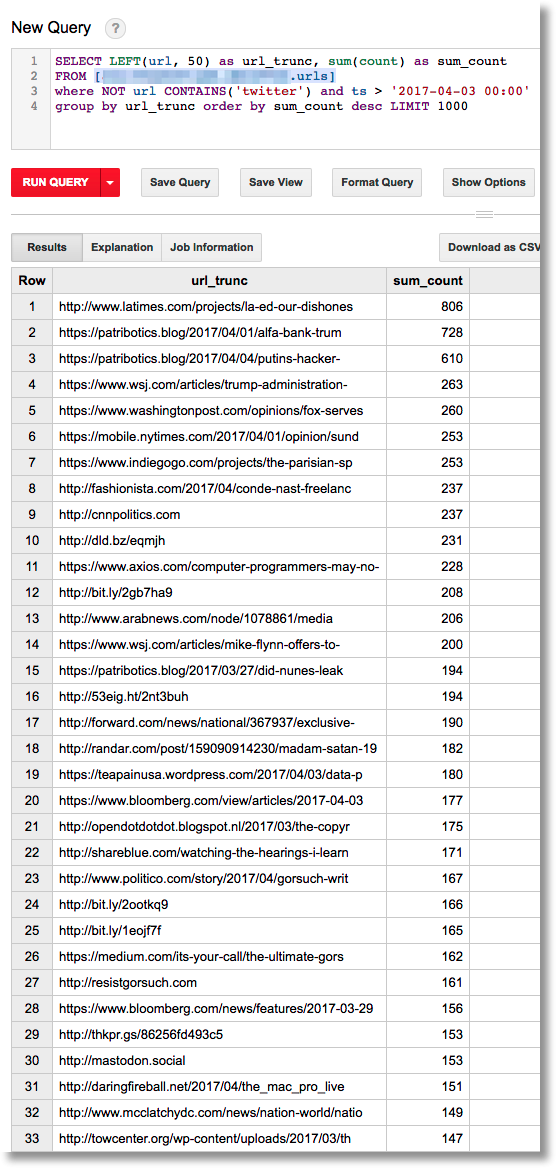
Or, find the most often-tweeted URLs from the past few days (some URLs are truncated in the output):
Summary… and what’s next?
In this post, we’ve looked at how you can programmatically launch Dataflow pipelines — that read from Datastore — directly from your App Engine app. See the example app’s README for more detail on how to configure and run the app yourself.
Dataflow’s expressive programming model makes it easy to build and support a wide range of scalable processing and analytics tasks. We hope you find the example app useful as a starting point towards defining new pipelines and running your own analytics from your App Engine apps. We look forward to hearing more about what you build!