Using Preemptible GPU-enabled VMs for Kubeflow Pipelines
Introduction
In this post, we’ll show how you can use preemptible GPU-provisioned VMs when running Kubeflow Pipelines jobs, to reduce costs. We’ll also look at how you can use Stackdriver Monitoring to inspect logs for both current and terminated pipeline operations.
Preemptible VMs are Compute Engine VM instances that last a maximum of 24 hours and provide no availability guarantees. The pricing of preemptible VMs is lower than that of standard Compute Engine VMs. With Google Kubernetes Engine (GKE), it is easy to set up a cluster or node pool that uses preemptible VMs. You can set up such a node pool with GPUs attached to the preemptible instances. These work the same as regular GPU-enabled nodes, but the GPUs persist only for the life of the instance.
Kubeflow is an open-source project dedicated to making deployments of machine learning (ML) workflows on Kubernetes simple, portable and scalable. Kubeflow Pipelines is a platform for building and deploying portable, scalable machine learning (ML) workflows based on Docker containers.
If you’re running Kubeflow on GKE, it is now easy to define and run Kubeflow Pipelines in which one or more pipeline steps (components) run on preemptible nodes, reducing the cost of running a job. For use of preemptible VMs to give correct results, the steps that you identify as preemptible should either be idempotent (that is, if you run a step multiple times, it will have the same result), or should checkpoint work so that the step can pick up where it left off if interrupted.
For example, a copy of a Google Cloud Storage (GCS) directory will have the same results if it’s interrupted and run again (assuming the source directory is unchanging). An operation to train a machine learning (ML) model (e.g., a TensorFlow training run) will typically be set up to checkpoint periodically, so if the training is interrupted by preemption, it can just pick up where it left off when the step is restarted. Most ML frameworks make it easy to support checkpointing, and so if your Kubeflow Pipeline includes model training steps, these are a great candidate for running on preemptible GPU-enabled nodes.
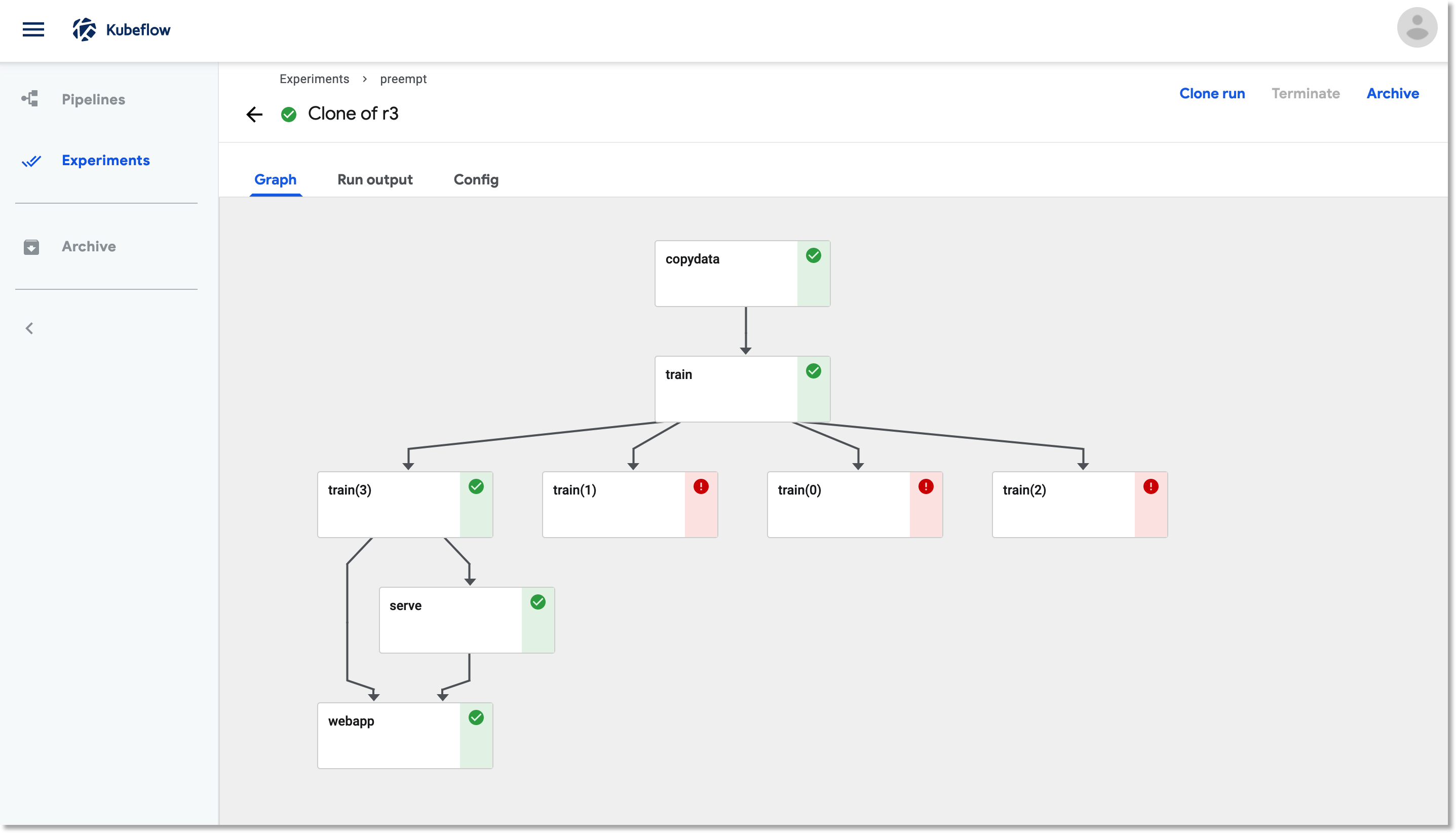
A Kubeflow Pipelines job that is using preemptible VMs for its training. When a training step is terminated due to preemption, it is restarted, and picks up where it left off using checkpoint information.
When you’re running a pipeline and a cluster node is preempted, any pods running on that node will be terminated as well. You’ll often want to look at the logs from these terminated pods. Cloud Platform’s Stackdriver logging makes it easy to do this.
In this post, we’ll look at how to use preemptible VMs with Kubeflow Pipelines, and how to inspect pipeline steps using Stackdriver.
Set up a preemptible GPU node pool in your GKE cluster
You can set up a preemptible, GPU-enabled node pool for your cluster by running a command similar to the following, editing the following command with your cluster name and zone, and adjusting the accelerator type and count according to your requirements. As shown below, you can also define the node pool to autoscale based on current workloads.
gcloud container node-pools create preemptible-gpu-pool \
--cluster=<your-cluster-name> \
--zone <your-cluster-zone> \
--enable-autoscaling --max-nodes=4 --min-nodes=0 \
--machine-type n1-highmem-8 \
--preemptible \
--node-taints=preemptible=true:NoSchedule \
--scopes cloud-platform --verbosity error \
--accelerator=type=nvidia-tesla-k80,count=4
You can also set up the node pool via the Cloud Console.
Note: You may need to increase your GPU quota before running this command. (Make sure you request quota for the zone in which your cluster is running).
Defining a Kubeflow Pipeline that uses the preemptible GKE nodes
When you’re defining a Kubeflow Pipeline, you can indicate that a given step should run on a preemptible node by modifying the op like this:
your_pipelines_op.apply(gcp.use_preemptible_nodepool())
See the documentation for details— if you changed the node taint from the above when creating the node pool, pass the same node toleration to the use_preemptible_nodepool() call.
You’ll presumably also want to retry the step some number of times if the node is preempted. You can do this as follows— here, we’re specifying 5 retries. This annotation also specifies that the op should run on a node with 4 GPUs available.
your_pipelines_op.set_gpu_limit(4).apply(gcp.use_preemptible_nodepool()).set_retry(5)
An example: making model training cheaper with preemptible nodes
Let’s look at a concrete example. The Kubeflow Pipeline from this codelab is a good candidate for using preemptible steps. This pipeline trains a Tensor2Tensor model on GitHub issue data, learning to predict issue titles from issue bodies, deploys the trained model for serving, and then deploys a webapp to get predictions from the model. It has a uses a TensorFlow model architecture that requires GPUs for reasonable performance, and— depending upon configuration— can run for quite a long time. I thought it would be useful to modify this pipeline to make use of the new support for preemptible VMs for the training. (Here is the original pipeline definition.)
To do this, I first needed to refactor the pipeline, to separate a GCS copy action from the model training activity. In the original version of this pipeline, a copy of an initial TensorFlow checkpoint directory to a working directory was bundled with the training. This refactoring was required for correctness: if the training is preempted and needs to be restarted, we don’t want to wipe out the current checkpoint files with the initial ones.
While I was at it, I created reusable component specifications for the two GCS copy and TensorFlow training pipeline steps, rather than defining these pipeline steps as part of the pipeline definition. A reusable component is a pre-implemented standalone component that is easy to add as a step in any pipeline, and makes the pipeline definition simpler. The component specification makes it easy to add static type checking of inputs and outputs as well. You can see these component definition files here and here.
Here is the relevant part of the new pipeline definition:
import kfp.dsl as dsl
import kfp.gcp as gcp
import kfp.components as comp
...
copydata_op = comp.load_component_from_url(
'https://raw.githubusercontent.com/amygdala/kubeflow-examples/preempt/github_issue_summarization/pipelines/components/t2t/datacopy_component.yaml'
)
train_op = comp.load_component_from_url(
'https://raw.githubusercontent.com/amygdala/kubeflow-examples/preempt/github_issue_summarization/pipelines/components/t2t/train_component.yaml'
)
@dsl.pipeline(
name='Github issue summarization',
description='Demonstrate Tensor2Tensor-based training and TF-Serving'
)
def gh_summ(
train_steps=2019300,
project='YOUR_PROJECT_HERE',
github_token='YOUR_GITHUB_TOKEN_HERE',
working_dir='YOUR_GCS_DIR_HERE',
checkpoint_dir='gs://aju-dev-demos-codelabs/kubecon/model_output_tbase.bak2019000',
deploy_webapp='true',
data_dir='gs://aju-dev-demos-codelabs/kubecon/t2t_data_gh_all/'
):
copydata = copydata_op(
working_dir=working_dir,
data_dir=data_dir,
checkpoint_dir=checkpoint_dir,
model_dir='%s/%s/model_output' % (working_dir, ''),
action=COPY_ACTION
).apply(gcp.use_gcp_secret('user-gcp-sa'))
train = train_op(
working_dir=working_dir,
data_dir=data_dir,
checkpoint_dir=checkpoint_dir,
model_dir='%s/%s/model_output' % (working_dir, ''),
action=TRAIN_ACTION, train_steps=train_steps,
deploy_webapp=deploy_webapp
).apply(gcp.use_gcp_secret('user-gcp-sa'))
train.after(copydata)
train.set_gpu_limit(4).apply(gcp.use_preemptible_nodepool()).set_retry(5)
train.set_memory_limit('48G')
...
I’ve defined the copydata and train steps using the component definitions, in this case loaded from URLs. (While not shown here, a Github-based component URL can include a specific git commit hash, thus supporting component version control— here’s an example of that.)
I’ve annotated the training op to run on a preemptible GPU-enabled node, and to retry 5 times. (For a long training job, you’d want to increase that number). You can see the full pipeline definition here.
(As a side note: it would have worked fine to use preemptible VMs for the copy step too, since if it is interrupted, it can be rerun without changing the result.)
Preemptible pipelines in action
When the pipeline above is run, its training step may be preempted and restarted. If this happens, it will look like this in the Kubeflow Pipelines dashboard UI:
A pipeline with a preemptible training step that has been restarted two times.
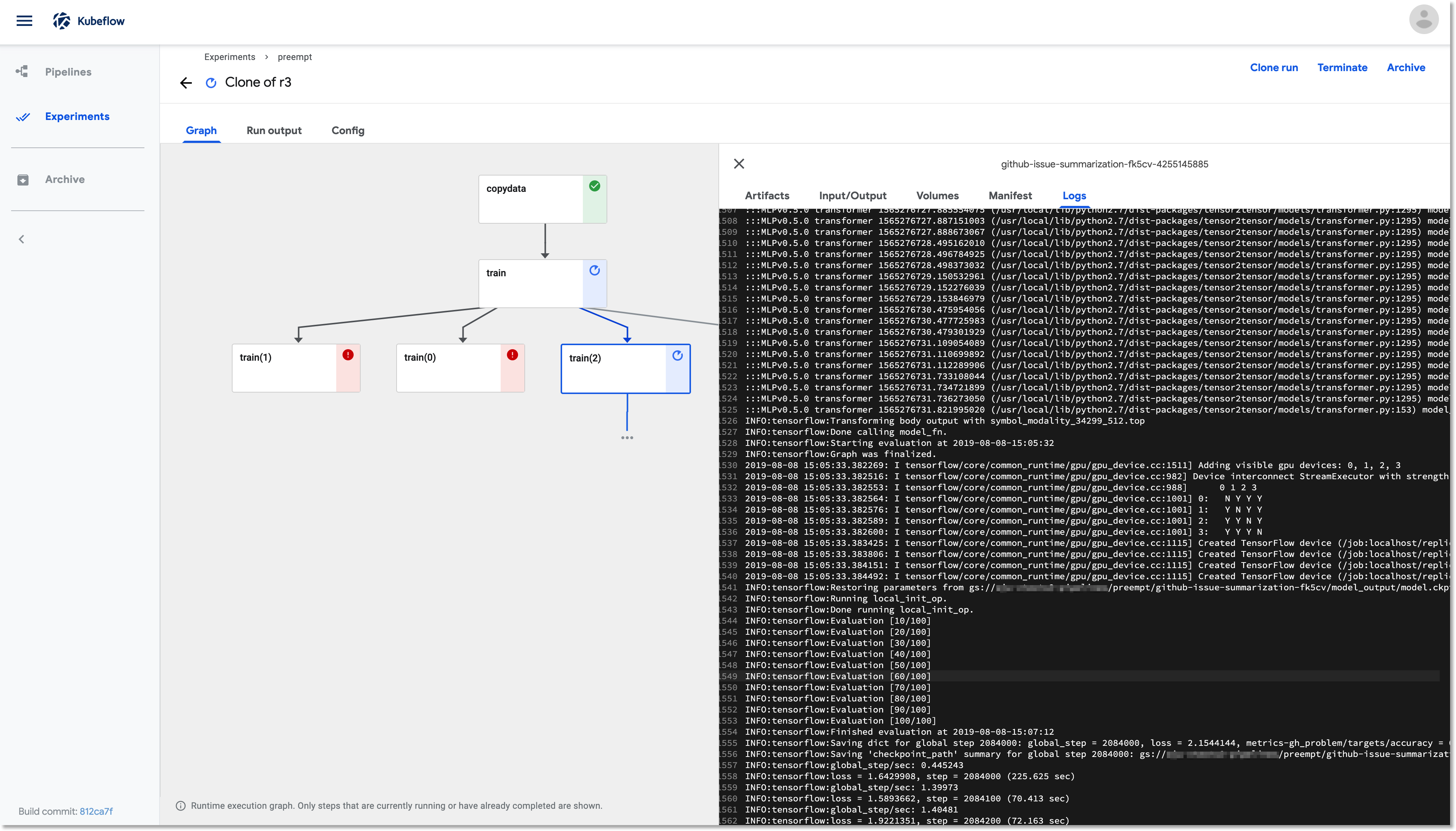
The restarted training step picks up where it left off, using its most recent saved checkpoint. In this screenshot, we’re using the Pipelines UI to look at the logs for the running training pod, train(2).
If we want to look at the logs for a pod terminated by node preemption, we can do this using Stackdriver.
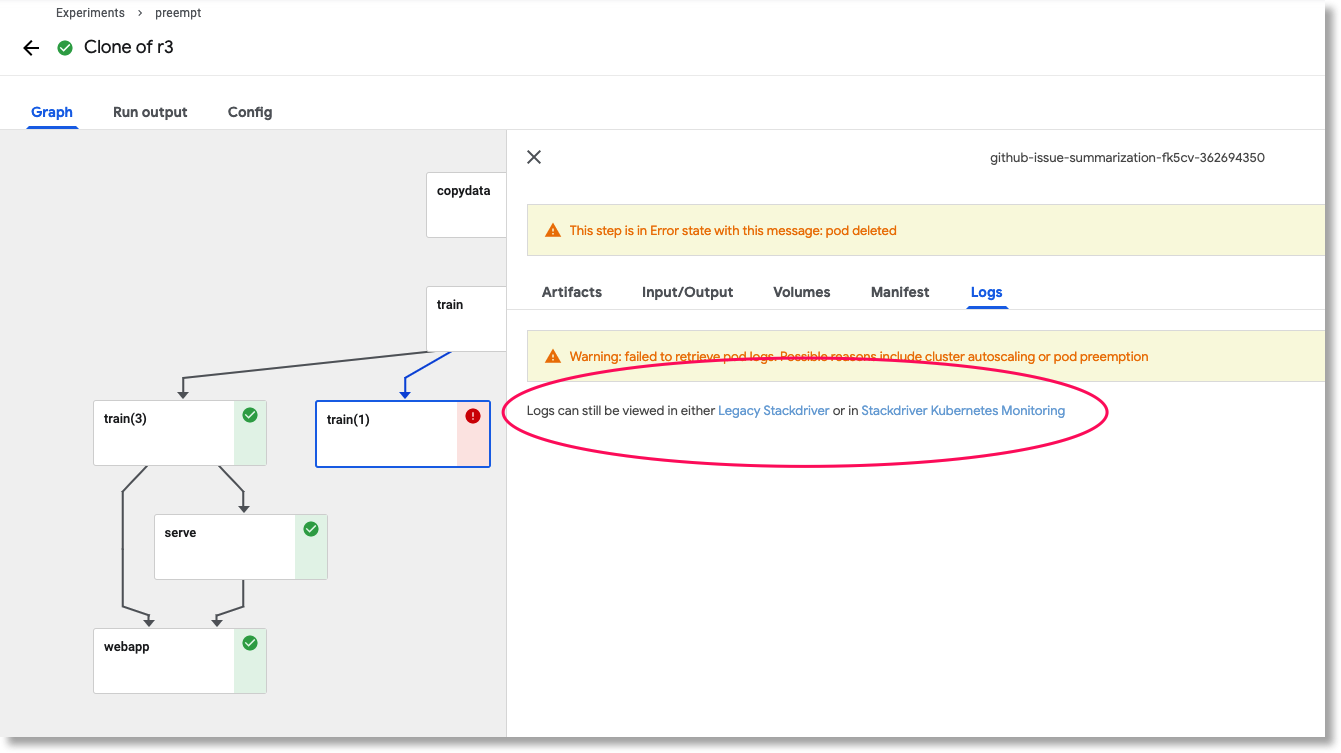
If the pod for a pipeline step has been deleted, a link is provided to look at the logs in Stackdriver.
Clicking the stackdriver link opens a window that brings up the Stackdriver Log Viewer in the Cloud Console, and sets a filter that selects the output for that pod.
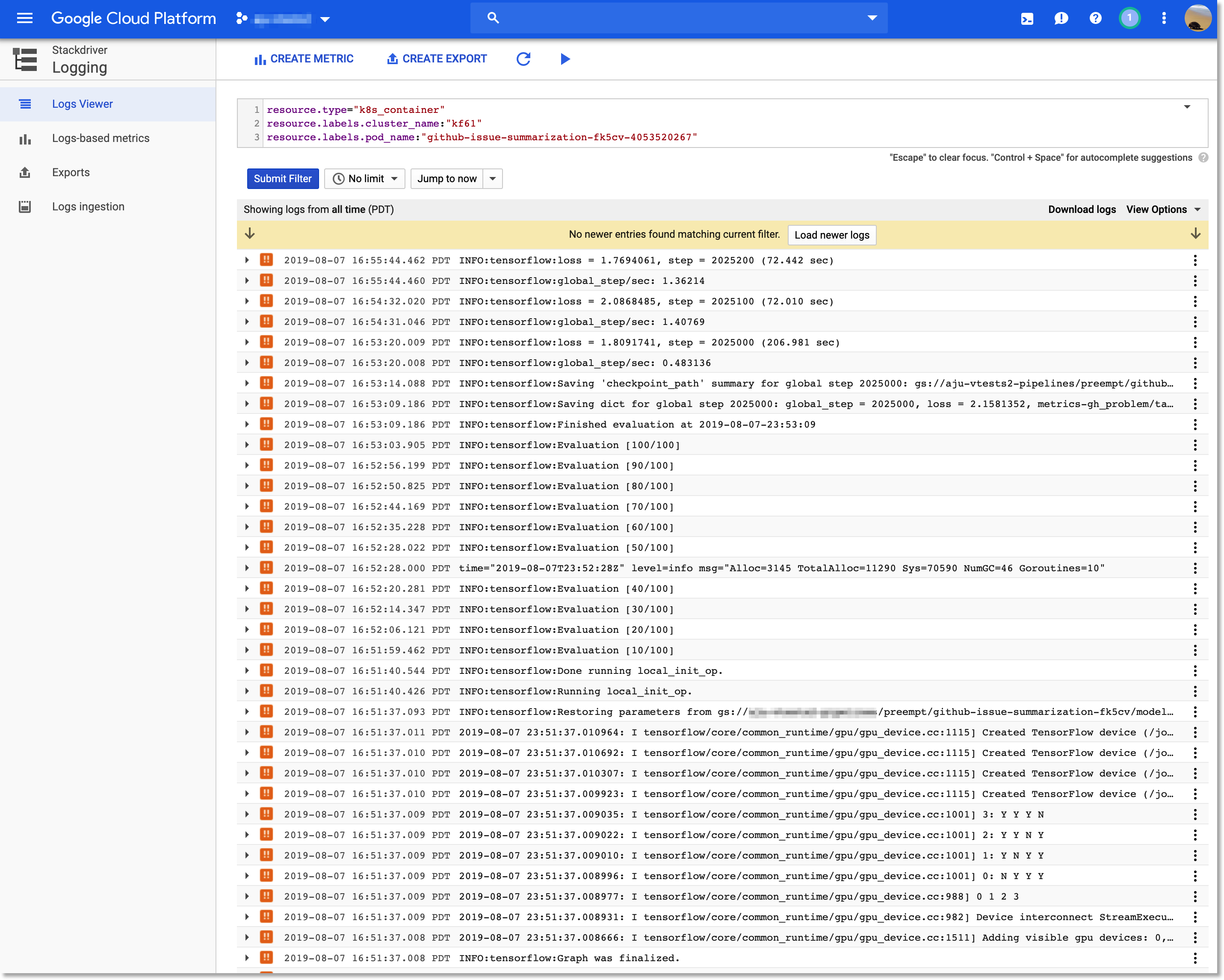
Clicking the 'Stackdriver' link in the Kubeflow Pipelines UI takes you to the relevant logs in the Cloud Console.
At some later point, the training run completes— in the figure below, after three premptions and retries— and the remainder of the pipeline runs.
The full pipeline run, with training completed after 3 preemptions.
What’s next?
In this post, I showed how you can use preemptible VMs for your Kubeflow Pipelines jobs in order to reduce costs.
To learn more about Kubeflow, including Kubeflow Pipelines, and to try it out yourself, the Kubeflow documentation and examples repo are good starting points. You might also be interested in this recent Kubeflow Community meeting presentation on what’s new in the Kubeflow 0.6 release.
You may also want to take a look at the ‘lightweight’ Kubeflow Pipelines deployer, which allows someone who is not a GCP Project-level admin to deploy Kubeflow Pipelines onto an existing cluster.