Running Cloud Dataflow template jobs from App Engine Standard
This post [***… templates… runtime vars… **]
This post builds on a previous post, which showed how you can periodically launch a Python Dataflow pipeline from App Engine, in order to support MapReduce jobs and other data processing and analysis tasks.
The pipeline used in this example analyzes data stored in Cloud Datastore — in this case, stored tweets from Twitter. The pipeline does several sorts of analysis on the tweet data; for example, it identifies ‘interesting’ word co-occurrences (bigrams) in the tweets.

This earlier example used a GAE Flexible
service
to periodically launch a Python Dataflow pipeline. This was necessary at the time, because we needed to install the gcloud sdk in the instance container(s) in order to launch the pipelines.
Since then, Cloud Dataflow job templates have come into the picture for the Python SDK. Dataflow templates allow you to stage your pipelines on Google Cloud Storage and execute them from a variety of environments. This can have a number of benefits:
- With templates, you don’t have to recompile your code every time you execute a pipeline.
- This means that you don’t need to launch your pipeline from a development environment or worry about dependencies.
- It’s much easier for non-technical users to launch pipelines using templates. There’s a REST API; and you can use
the Google Cloud Platform Console, or launch via the
gcloudcommand-line interface.
In this post, we’ll show how to use the Dataflow job template REST API to periodically launch the Tweet-analytics Dataflow pipeline described in the earlier post. Because we’re now just calling a REST API, and no longer need to use the gcloud sdk, we can build a simpler App Engine Standard app.
With templates, you can use runtime parameters to customize the execution. We’ll use that feature in this example. (There are some current limitations on where you can use runtime parameters, and we’ll see an example of that as well).
Defining a parameterized Dataflow pipeline and creating a template
The first step in building our app is defining and creating a Dataflow template.
…. parameterized pipeline …. the pipeline definition in dfpipe/pipe.py to build the template. As part
of the pipeline definition, it’s specified that the pipeline takes a runtime argument, timestamp.
class UserOptions(PipelineOptions):
@classmethod
def _add_argparse_args(cls, parser):
parser.add_value_provider_argument('--timestamp', type=str)
Then in the pipeline, that arg can be accessed ….
user_options = pipeline_options.view_as(UserOptions)
...
wc_records = top_percents | 'format' >> beam.FlatMap(
lambda x: [{'word': xx[0], 'percent': xx[1],
'ts': user_options.timestamp.get()} for xx in x])
The template creation script accesses the pipeline definition
… https://cloud.google.com/dataflow/docs/templates/creating-templates#creating-and-staging-templates …
… and uses the --template_location flag…
pipeline_options = {
'project': PROJECT,
'staging_location': 'gs://' + BUCKET + '/staging',
'runner': 'DataflowRunner',
'setup_file': './setup.py',
'job_name': PROJECT + '-twcount',
'temp_location': 'gs://' + BUCKET + '/temp',
'template_location': 'gs://' + BUCKET + '/templates/' + PROJECT + '-twproc_tmpl'
}
pipeline_options = PipelineOptions.from_dictionary(pipeline_options)
pipe.process_datastore_tweets(PROJECT, DATASET, pipeline_options)
Once the template is created, we’ll use it to launch dataflow pipeline jobs from our GAE app….
Launching a Dataflow template job from the cloud console
Now that you’ve created a pipeline template, you can test it out by launching a job based on that template from the
Cloud Console. (You could also do this via the gcloud command-line tool).
While it’s not strictly necessary to do this prior to deploying your GAE app, it’s a good sanity check.
Note that the pipeline won’t do anything interesting unless you already have tweet data in the Datastore.
Go to the Dataflow pane of the Cloud Console, and click on “Create Job From Template”.

Select “Custom Template”, then browse to your new template’s location in GCS. This info was output when you ran
create_template.py. (The pulldown menu includes some predefined templates as well, that you may want to explore).
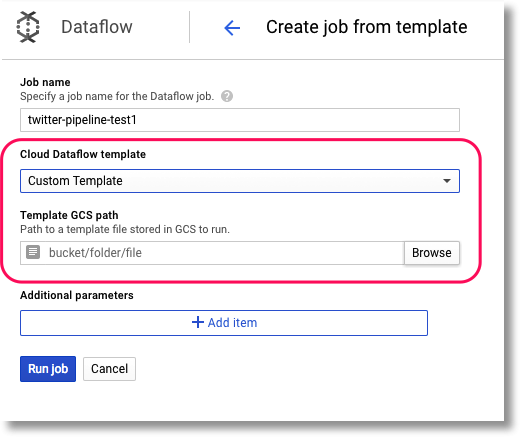
Finally, set your pipeline’s runtime parameter(s). In this case, we have one: timestamp. The pipeline is expecting a
value in a format like this: 2017-10-22 10:18:13.491543 (you can generate such a string in python via
str(datetime.datetime.now())).
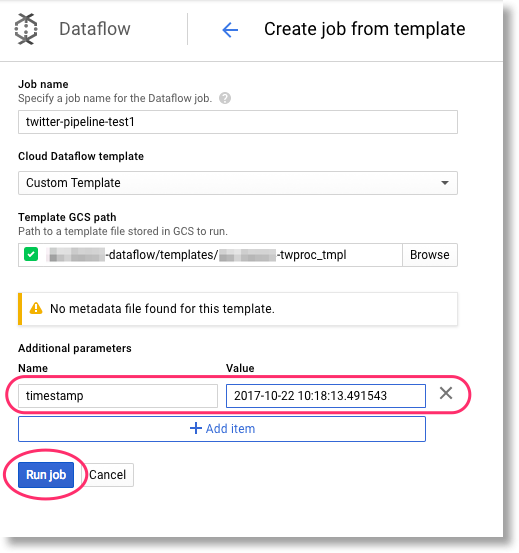
Note that while we don’t show it here, you can extend your templates with additional metadata so that custom parameters may be validated when the template is executed.
Template runtime parameters and pipeline data sources
…
Overview of the App Engine app
…a GAE Standard app that periodically pulls in timeline tweets from Twitter and stores them in Datastore; and launches… serves as a cron job…
…the part that gathers the tweets– is just for example purposes; in your own apps, you probably already have some other means of collecting and storing data in Datastore.
xxxx
The Python code for the app consists of a webapp script (main.py), which does two things: [** pulls in tweets
periodically, and launches a DF pipeline via the template periodically **]
accesses a module (dfpipe) that does most of the heavy lifting in terms of defining and launching the example pipeline
(in dfpipe/pipe.py).
Setting the pipeline options
As part of the process of launching a Dataflow pipeline, various options may be set.
In order to make the dfpipe module available to the Dataflow workers, the pipeline options include a setup_file flag.
pipeline_options = {
'project': PROJECT,
'staging_location': 'gs://' + BUCKET + '/staging',
'runner': 'DataflowRunner',
'setup_file': './setup.py',
'job_name': PROJECT + '-twcount',
'max_num_workers': 10,
'temp_location': 'gs://' + BUCKET + '/temp'
}
This points to a setup.py file which specifies to package the dfpipe module using setuptools. If our pipeline also had dependencies on third-party libs, we could include those in setup.py as well.
The indicated code is gathered in a package that is built as a source distribution, staged in the staging area for the workflow being run, and then installed in the workers when they start running.
A look at the Dataflow pipeline
Now let’s take a quick look at dfpipe/pipe.py, to see what the Python Dataflow pipeline does.
It reads recent tweets from the past N days from Cloud Datastore, then essentially splits into three processing branches. It finds the top N most popular words in terms of the percentage of tweets they were found in, calculates the top N most popular URLs in terms of their count, and then derives relevant word co-occurrences (bigrams) using an approximation to a tf*idf ranking metric. It writes the results to three BigQuery tables. (It would be equally straightforward to write results to Datastore instead/as well).

Using Datastore as a pipeline source
….
Launching the Dataflow pipeline periodically using a cron job
In the example app, we want to launch a pipeline job every few hours, where each job analyzes the tweets from the past few days, providing a ‘moving window’ of analysis. So, it makes sense to just set things up as an app cron job, which looks like this:
cron:
- description: fetch tweets
url: /timeline
schedule: every 17 minutes
target: default
- description: launch dataflow pipeline
url: /launchtemplatejob
schedule: every 5 hours
target: default
A pipeline job could of course be triggered by other means as well– e.g. as part of handling a client request to the app, or perhaps via a Task Queue task.
A look at the example results in BigQuery
Once our example app is up and running, it periodically runs a Dataflow job that writes the results of its analysis to BigQuery. (It would be just as easy to write results to the Datastore if that makes more sense for your workflow – or to write to multiple sources).
With BigQuery, it is easy to run some fun queries on the data. For example, we can find recent word co-occurrences that are ‘interesting’ by our metric:

Or look for emerging word pairs, that have become ‘interesting’ in the last day or so (as of early April 2017):

We can contrast the ‘interesting’ word pairs with the words that are simply the most popular within a given period (you can see that most of these words are common, but not particularly newsworthy):

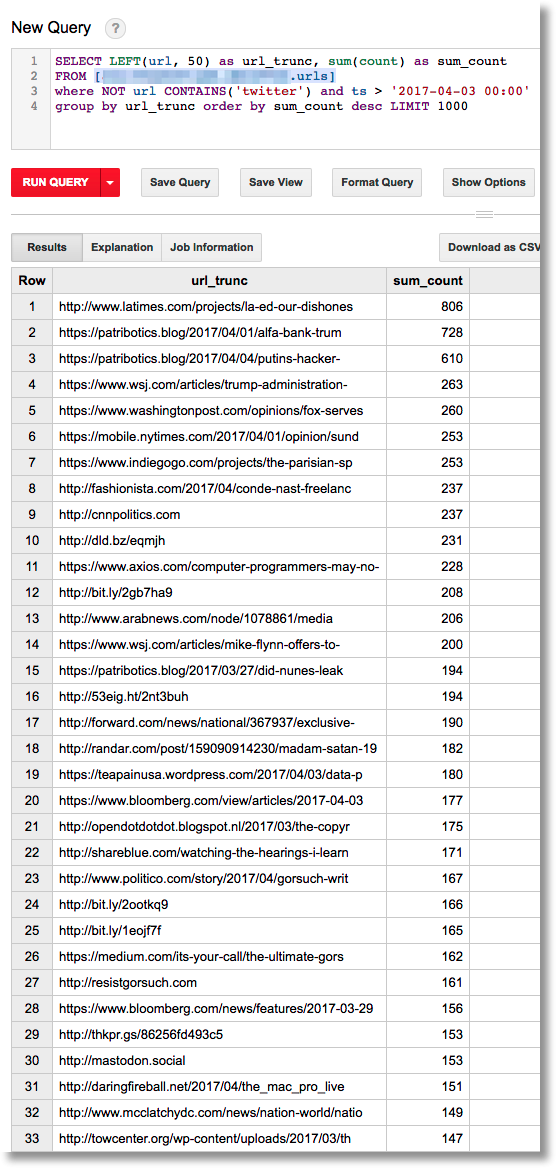
Or, find the most often-tweeted URLs from the past few days (some URLs are truncated in the output):
Summary… and what’s next?
In this post, we’ve looked at how you can programmatically launch Dataflow pipelines — that read from Datastore — directly from your App Engine app. See the example app’s README for more detail on how to configure and run the app yourself.
Dataflow’s expressive programming model make it easy to build and support a wide range of scalable processing and analytics tasks. We hope you find the example app useful as a starting point towards defining new pipelines and running your own analytics from your App Engine apps. We look forward to hearing more about what you build!