Using Cloud Dataflow pipeline templates from App Engine
Introduction
This post describes how to use Cloud Dataflow job templates to easily launch Dataflow pipelines from a Google App Engine (GAE) app, in order to support MapReduce jobs and many other data processing and analysis tasks.
This post builds on a previous post, which
used a GAE Flexible
service
to periodically launch a Python Dataflow pipeline. The use of GAE Flex was necessary at the time, because we needed
to install the gcloud sdk in the instance container(s) in order to launch the pipelines.
Since then, Cloud Dataflow templates have come into the picture for the Python SDK. Dataflow templates allow you to stage your pipelines on Google Cloud Storage and execute them from a variety of environments. This has a number of benefits:
- With templates, you don’t have to recompile your code every time you execute a pipeline.
- This means that you don’t need to launch your pipeline from a development environment or worry about dependencies.
- It’s much easier for non-technical users to launch pipelines using templates. You can launch via
the Google Cloud Platform Console, the
gcloudcommand-line interface, or the REST API.
In this post, we’ll show how to use the Dataflow job template
REST API
to periodically launch a Dataflow templated job from GAE. Because we’re now simply calling an
API, and no longer relying on the gcloud sdk to launch from App Engine, we can build a simpler App Engine
Standard app.
With templates, you can use runtime parameters to customize the execution. We’ll use that feature in this example too.
The pipeline used in this example is nearly the same as that described in the earlier post; it analyzes data stored in Cloud Datastore — in this case, stored tweets fetched periodically from Twitter. The pipeline does several sorts of analysis on the tweet data; for example, it identifies important word co-occurrences in the tweets, based on a variant of the tf*idf metric.

Defining a parameterized Dataflow pipeline and creating a template
The first step in building our app is creating a Dataflow template. We do this by building a pipeline and then
deploying
it with the --template_location flag, which causes the template to be compiled and stored at the given
Google Cloud Storage (GCS) location.
You can see the pipeline definition here. It reads recent tweets from the past N days from Cloud Datastore, then splits into three processing branches. It finds the most popular words in terms of the percentage of tweets they were found in, calculates the most popular URLs in terms of their count, and then derives relevant word co-occurrences using an approximation to a tf*idf ranking metric. It writes the results to three BigQuery tables. (It would be equally straightforward to write results to Datastore instead/as well).

The previous post in this series goes into a bit more detail about what some of the pipeline steps do, and how the pipeline accesses the Datastore.
As part of our new template-ready pipeline definition, we’ll specify that the pipeline takes a
runtime argument,
named timestamp. This value is used to filter out tweets N days older than the timestamp, so that the pipeline analyzes
only recent activity.
class UserOptions(PipelineOptions):
@classmethod
def _add_argparse_args(cls, parser):
parser.add_value_provider_argument('--timestamp', type=str)
Then, that argument can be accessed at runtime from a template-generated pipeline, as in this snippet:
user_options = pipeline_options.view_as(UserOptions)
...
wc_records = top_percents | 'format' >> beam.FlatMap(
lambda x: [{'word': xx[0], 'percent': xx[1],
'ts': user_options.timestamp.get()} for xx in x])
The example includes a template creation utility script called create_template.py, which
sets some pipeline options, including the --template_location flag, defines the pipeline (via pipe.process_datastore_tweets()), and calls run() on it. The core of this script is shown below.
Note that the pipeline_options dict doesn’t include timestamp; we’ll define that
at runtime, not compile time.
import dfpipe.pipe as pipe
...
pipeline_options = {
'project': PROJECT,
'staging_location': 'gs://' + BUCKET + '/staging',
'runner': 'DataflowRunner',
'setup_file': './setup.py',
'job_name': PROJECT + '-twcount',
'temp_location': 'gs://' + BUCKET + '/temp',
'template_location': 'gs://' + BUCKET + '/templates/' + PROJECT + '-twproc_tmpl'
}
pipeline_options = PipelineOptions.from_dictionary(pipeline_options)
pipe.process_datastore_tweets(PROJECT, DATASET, pipeline_options)
Because we used the --template_location flag, a template for that pipeline
is compiled and saved to the indicated GCS location (rather than triggering a run of the pipeline).
Now that the template is created, we can use it to launch Dataflow pipeline jobs from our GAE app.
A note on input sources and template runtime arguments
As you can see from this table in the documentation, the Dataflow Python SDK does not yet support the use of runtime parameters with Datastore input.
For pipeline analysis, we want to consider only Datastore data from the last N days.
But, because of the above constraint, we can’t access the runtime timestamp parameter when we’re constructing the
Datastore reader query. (If you try, you will see a compile-time error). Similarly, if you try the approach taken by
the non-template version of the pipeline here,
which uses datetime.datetime.now() to construct its Datastore query, you’ll find that you’re always using the same
compile-time static timestamp each time you run the template.
To work around this for the template version of this pipeline, we will include a filter step, that can access runtime parameters, and which filters out all but the last N days of tweets post-query.
You can see this step as FilterDate in the Dataflow pipeline graph figure above.
Launching a Dataflow templated job from the Cloud Console
Before we actually deploy the GAE app, let’s check that we can launch a properly running Dataflow templated job
from our newly generated template. We can do that by launching a job based on that template from Cloud
Console. (You could also do this via the gcloud command-line tool). Note that the
pipeline won’t do anything interesting unless you already have Tweet data in the Datastore— which would be the case if
you tried the earlier example in this
series— but you can still confirm that it launches and runs successfully.
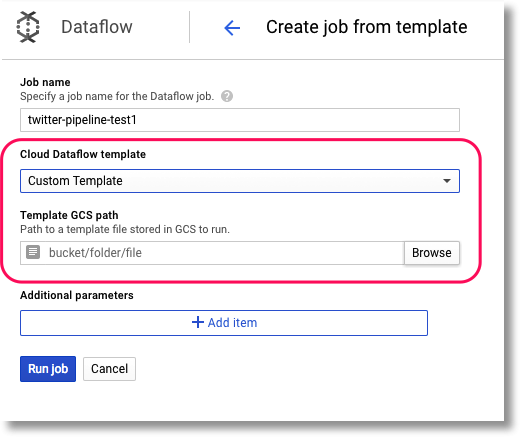
Go to the Dataflow pane of Cloud Console, and click “Create Job From Template”.

Select “Custom Template”, then browse to your new template’s location in GCS. This info was output when you ran
create_template.py. (The pulldown menu also includes some predefined templates that you may want to explore later).
Finally, set your pipeline’s defined runtime parameter(s). In this case, we have one: timestamp. The pipeline is
expecting a value in a format like this:
2017-10-22 10:18:13.491543 (you can generate such a string in the Python interpreter via str(datetime.datetime.now())).
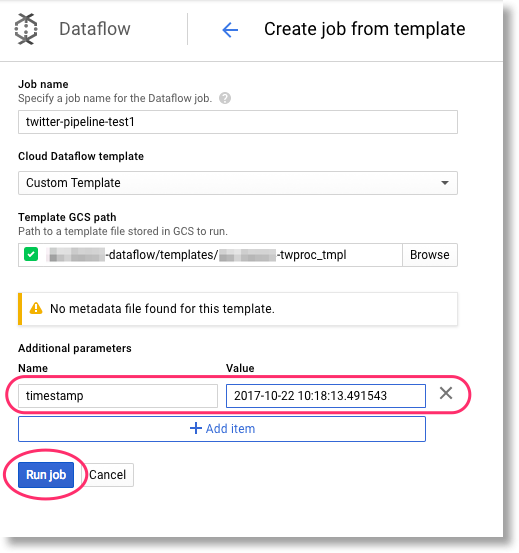
While we don’t show it here, you can extend your templates with additional metadata so that custom parameters may be validated when the template is executed.
Once you click ‘Run Job’, you should be able to see your job running in Cloud Console.
Using an App Engine app to periodically launch Dataflow jobs (and fetch Tweets)
Now that we’ve checked that we can successfully launch a Dataflow job using our template, we’ll define an App Engine app handler to launch such jobs via the Dataflow job template REST API, and run that handler periodically via a GAE cron. We’ll use another handler of the same app to periodically fetch tweets and store them in the Datastore.
You can see the GAE app script here.
The FetchTweets handler fetches tweets and stores them in the Datastore.
See the previous post in this series for a bit more info on that. However, this part of the app is just
for example purposes; in your own apps, you probably already have some other means of collecting and storing data in Datastore.
The LaunchJob handler is the new piece of the puzzle: using the Dataflow REST API, it sets the timestamp runtime parameter, and launches a Dataflow job using the template.
from googleapiclient.discovery import build
from oauth2client.client import GoogleCredentials
...
credentials = GoogleCredentials.get_application_default()
service = build('dataflow', 'v1b3', credentials=credentials)
BODY = {
"jobName": "{jobname}".format(jobname=JOBNAME),
"gcsPath": "gs://{bucket}/templates/{template}".format(
bucket=BUCKET, template=TEMPLATE),
"parameters": {"timestamp": str(datetime.datetime.utcnow())},
"environment": {
"tempLocation": "gs://{bucket}/temp".format(bucket=BUCKET),
"zone": "us-central1-f"
}
}
dfrequest = service.projects().templates().create(
projectId=PROJECT, body=BODY)
dfresponse = dfrequest.execute()
logging.info(dfresponse)
self.response.write('Done')
Launching the Dataflow pipeline periodically using a GAE cron
For our GAE app, we want to launch a Dataflow templated job every few hours, where each job analyzes the tweets from the past few days, providing a ‘moving window’ of analysis. So, it makes sense to set things using a cron.yaml file like this:
cron:
- description: fetch tweets
url: /timeline
schedule: every 17 minutes
target: default
- description: launch dataflow pipeline
url: /launchtemplatejob
schedule: every 5 hours
target: default
A GAE app makes it easy to run such a cron, but note that now that we’re using templates, it becomes easier to to support this functionality in other ways too. E.g., it would also be straightforward to use the gcloud CLI to launch the template job, and set up a local cron job.
A look at the example results in BigQuery
Once our example app is up and running, it periodically runs a Dataflow job that writes the results of its analysis to BigQuery. (It would also be straightforward to write results to the Datastore if that makes more sense for your workflow – or to write to multiple sources).
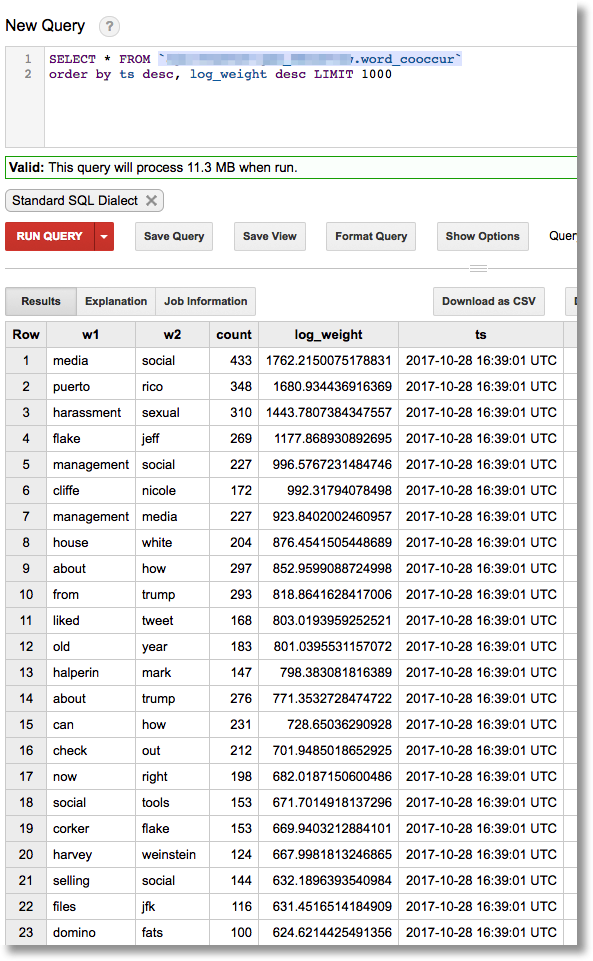
With BigQuery, it is easy to run some fun queries on the data. For example, we can find recent word co-occurrences that are ‘interesting’ by our metric:
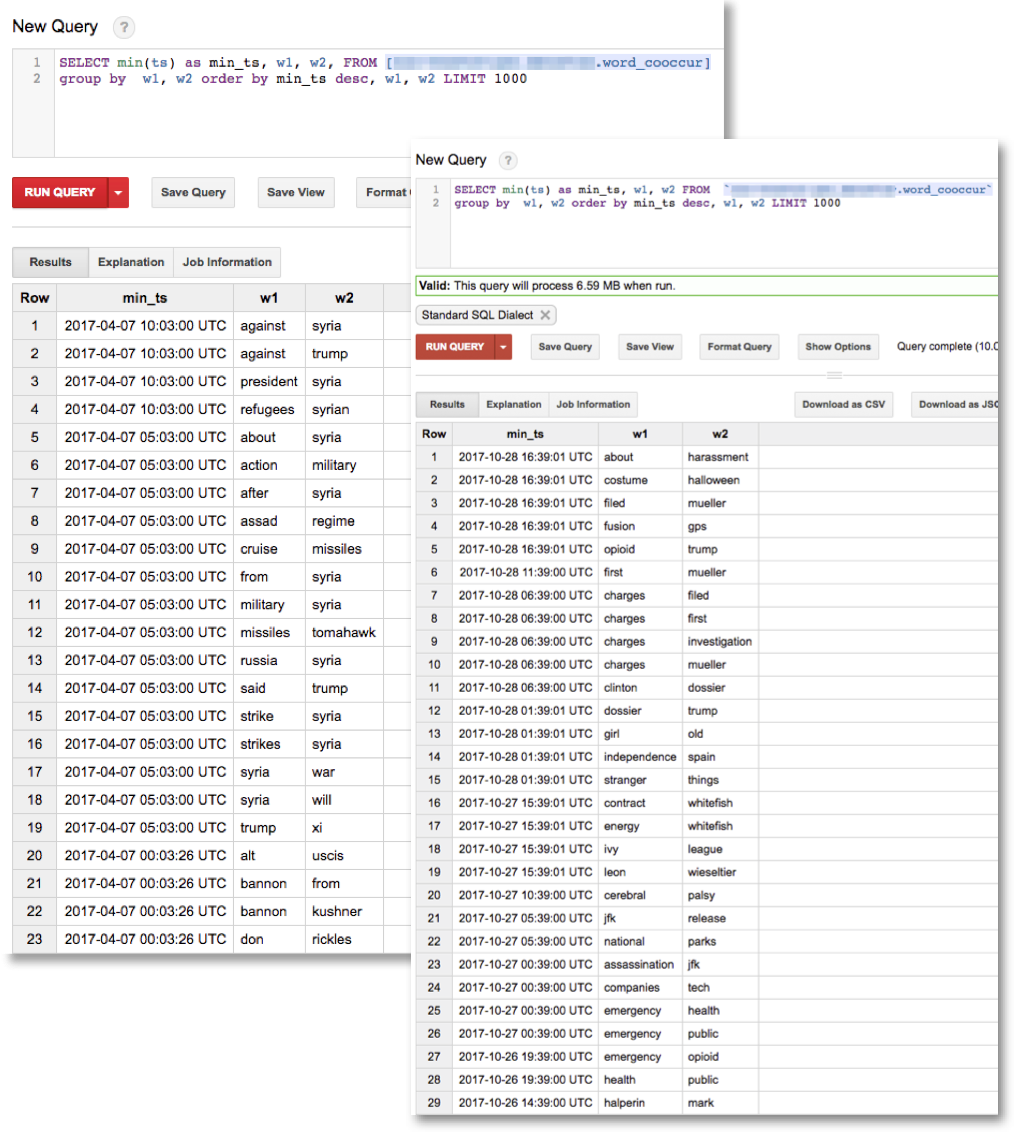
Or we can look for emergent word pairs, that have become ‘interesting’ in the last day or so (compare April and Oct 2017 results):
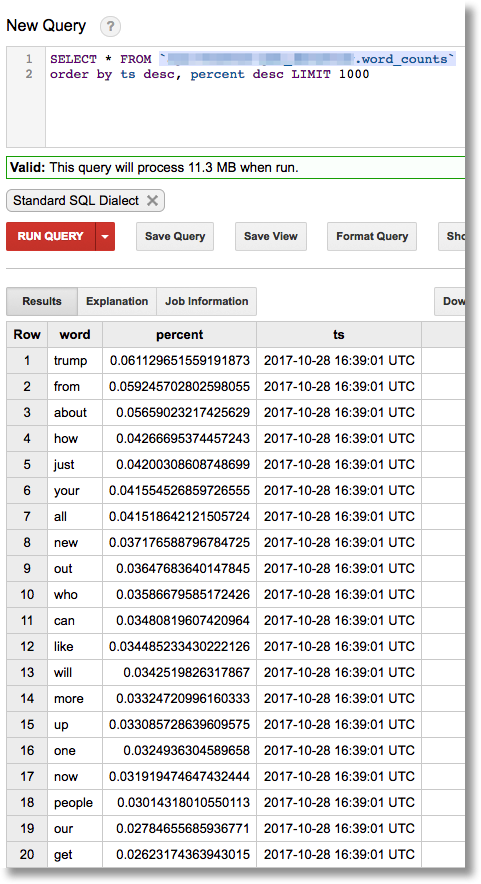
We can contrast the ‘interesting’ word pairs with the words that are simply the most popular within a given period (you can see that most of these words are common, but not particularly newsworthy):
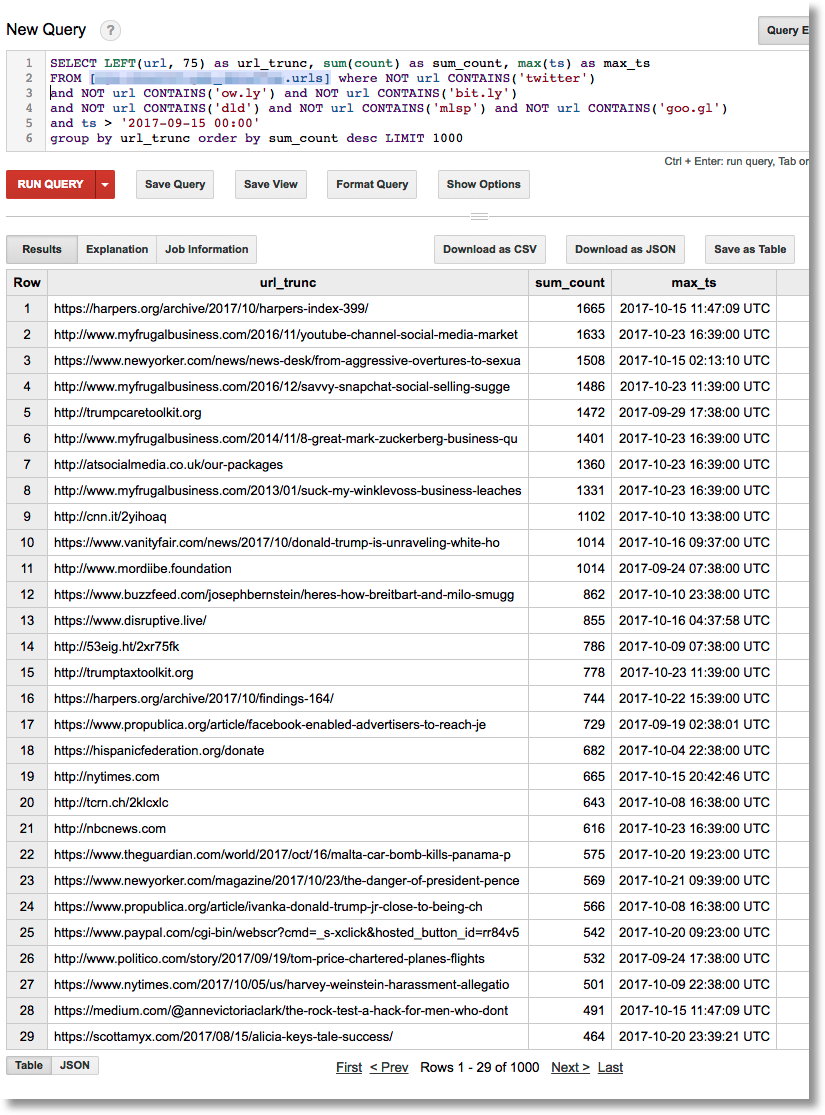
Or, find the most frequently tweeted URLs from the past few weeks (some URLs are truncated in the output):
Summary… and what’s next?
In this post, we’ve looked at how you can programmatically launch Dataflow pipelines — that read from Datastore — using Cloud Dataflow job templates, and call the Dataflow REST API from an App Engine app. See the example app’s README for more detail on how to configure and run the app yourself.
Dataflow’s expressive programming model makes it easy to build and support a wide range of scalable processing and analytics tasks. With templates, it becomes much easier to launch pipeline jobs — you don’t have to recompile every time you execute, or worry about your environment and dependencies. And it’s more straightforward for less technical users to launch template-based pipelines.
We hope you find the example app useful as a starting point towards defining new pipeline templates and running your own analytics — via App Engine apps or otherwise. We look forward to hearing more about what you build!