Running a distributed Keras HP Tuning search using Kubeflow Pipelines
How to use Kubeflow Pipelines to support HP Tuning using the Keras Tuner
- Introduction
- About the dataset and modeling task
- Keras tuner in distributed mode on GKE with preemptible VMs
- Defining the HP Tuning + training workflow as a pipeline
- What’s next?
Introduction
The performance of a machine learning model is often crucially dependent on the choice of good hyperparameters. For models of any complexity, relying on trial and error to find good values for these parameters does not scale. This tutorial shows how to use Cloud AI Platform Pipelines in conjunction with the Keras Tuner libraries to build a hyperparameter-tuning workflow that runs a distributed HP search on GKE.
Cloud AI Platform Pipelines, currently in Beta, provides a way to deploy robust, repeatable machine learning pipelines along with monitoring, auditing, version tracking, and reproducibility, and gives you an easy-to-install, secure execution environment for your ML workflows. AI Platform Pipelines is based on Kubeflow Pipelines (KFP) installed on a Google Kubernetes Engine (GKE) cluster, and can run pipelines specified via both the KFP and TFX SDKs. See this blog post for more detail on the Pipelines tech stack. You can create an AI Platform Pipelines installation with just a few clicks. After installing, you access AI Platform Pipelines by visiting the AI Platform Panel in the Cloud Console.
Keras Tuner is a distributable hyperparameter optimization framework. Keras Tuner makes it easy to define a search space and leverage included algorithms to find the best hyperparameter values. It comes with several search algorithms built-in, and is also designed to be easy for researchers to extend in order to experiment with new search algorithms. It is straightforward to run the Keras Tuner in distributed search mode, which we’ll leverage for this example.
The intent of a HP tuning search is typically not to do full training for each parameter combination, but to find the best starting points. The number of epochs run in the HP search trials are typically smaller than that used in the full training. So, an HP tuning-based ML workflow could include these steps:
- perform a distributed HP tuning search, and obtain the results
- do concurrent full training runs for each of the best
Nparameter configurations, and export (save) the model for each - serve (some of) the resultant models, often after model evaluation.
As indicated above, a Cloud AI Platform (KFP) Pipeline runs under the hood on a GKE cluster. This makes it straightforward to implement this workflow— leveraging GKE for the distributed HP search and model serving— so that you just need to launch a pipeline job to kick it off.
This post highlights an example pipeline that does that. The example also shows how to use preemptible GPU-enabled VMS for the HP search, to reduce costs; and how to use TF-serving to deploy the trained model(s) on the same cluster for serving. As part of the process, we’ll see how GKE provides a scalable, resilient platform with easily-configured use of accelerators.
About the dataset and modeling task
The dataset
The Cloud Public Datasets Program makes available public datasets that are useful for experimenting with machine learning. Just as with this “Explaining model predictions on structured data” post, we’ll use data that is essentially a join of two public datasets stored in BigQuery: London Bike rentals and NOAA weather data, with some additional processing to clean up outliers and derive additional GIS and day-of-week fields.
The modeling task and Keras model
We’ll use this dataset to build a Keras regression model to predict the duration of a bike rental based on information about the start and end stations, the day of the week, the weather on that day, and other data. If we were running a bike rental company, for example, these predictions—and their explanations—could help us anticipate demand and even plan how to stock each location.
We’ll build a parameterizable model architecture for this task (similar in structure to a “wide and deep” model), then use the Keras Tuner package to do an HP search using this model structure, as well as doing full model training using the best HP set(s).
Keras tuner in distributed mode on GKE with preemptible VMs
With the Keras Tuner, you set up a HP tuning search along these lines (the code is from the example; other search algorithms are supported in addition to ‘random’):
tuner = RandomSearch(
create_model,
objective='val_mae',
max_trials=args.max_trials,
distribution_strategy=STRATEGY,
executions_per_trial=args.executions_per_trial,
directory=args.tuner_dir,
project_name=args.tuner_proj
)
…where in the above, the create_model call takes takes an argument hp from which you can sample hyperparameters. For this example, we’re varying number of hidden layers, number of nodes per hidden layer, and learning rate in the HP search. There are many other hyperparameters that you might also want to vary in your search.
def create_model(hp):
inputs, sparse, real = bwmodel.get_layers()
...
model = bwmodel.wide_and_deep_classifier(
inputs,
linear_feature_columns=sparse.values(),
dnn_feature_columns=real.values(),
num_hidden_layers=hp.Int('num_hidden_layers', 2, 5),
dnn_hidden_units1=hp.Int('hidden_size', 32, 256, step=32),
learning_rate=hp.Choice('learning_rate',
values=[1e-1, 1e-2, 1e-3, 1e-4])
)
Then, call tuner.search(...). See the Keras Tuner docs for more.
The Keras Tuner supports running this search in distributed mode. Google Kubernetes Engine (GKE) makes it straightforward to configure and run a distributed HP tuning search. GKE is a good fit not only because it lets you easily distribute the HP tuning workload, but because you can leverage autoscaling to boost node pools for a large job, then scale down when the resources are no longer needed. It’s also easy to deploy trained models for serving onto the same GKE cluster, using TF-serving. In addition, the Keras Tuner works well with preemptible VMs, making it even cheaper to run your workloads.
With the Keras Tuner’s distributed config, you specify one node as the ‘chief’, which coordinates the search, and ‘tuner’ nodes that do the actual work of running model training jobs using a given param set (the trials). When you set up an HP search, you indicate the max number of trials to run, and how many executions to run per trial. The Kubeflow Pipeline allows dynamic specification of the number of tuners to use for a given HP search— this determines how many trials you can run concurrently— as well as the max number of trials and number of executions.
We’ll define the tuner components as Kubernetes jobs, each specified to have 1 replica. This means that if a tuner job pod is terminated for some reason prior to job completion, Kubernetes will start up another replica.
Thus, the Keras Tuner’s HP search is a good fit for use of preemptible VMs. Because the HP search bookkeeping— orchestrated by the tuner chief, via an ‘oracle’ file— tracks the state of the trials, the configuration is robust to a tuner pod terminating unexpectedly— say, due to a preemption— and a new one being restarted. The new job pod will get its instructions from the ‘oracle’ and continue running trials.
The example uses GCS for the tuners’ shared file system.
Once the HP search has finished, any of the tuners can obtain information on the N best parameter sets (as well as export the best model(s)).
Defining the HP Tuning + training workflow as a pipeline
The definition of the pipeline itself is here, specified using the KFP SDK. It’s then compiled to an archive file and uploaded to AI Platforms Pipelines. (To compile it yourself, you’ll need to have the KFP SDK installed). Pipeline steps are container-based, and you can find the Dockerfiles and underlying code for the steps under the example’s components directory.
The example pipeline first runs a distributed HP tuning search using a specified number of tuner workers, then obtains the best N parameter sets—by default, it grabs the best two. The pipeline step itself does not do the heavy lifting, but rather launches all the tuner jobs on GKE, which run concurrently, and monitors for their completion. (Unsurprisingly, this stage of the pipeline may run for quite a long time, depending upon how many HP search trials were specified and how many tuners are used for the distributed search).
Concurrently to the Keras Tuner runs, the pipeline sets up a TensorBoard visualization component, its log directory set to the GCS path under which the full training jobs are run.
The pipeline then runs full training jobs, concurrently, for each of the N best parameter sets. It does this via the KFP loop construct, allowing the pipeline to support dynamic specification of N. The training jobs can be monitored and compared using TensorBoard, both while they’re running and after they’ve completed.
Then, the trained models are deployed for serving for serving on the GKE cluster, using TF-serving. Each deployed model has its own cluster service endpoint. (While not included in this example, one could insert a step for model evaluation before making the decision about whether to deploy to TF-serving.)
For example, here is the DAG for a pipeline execution that did training and then deployed prediction services for the two best parameter configurations.
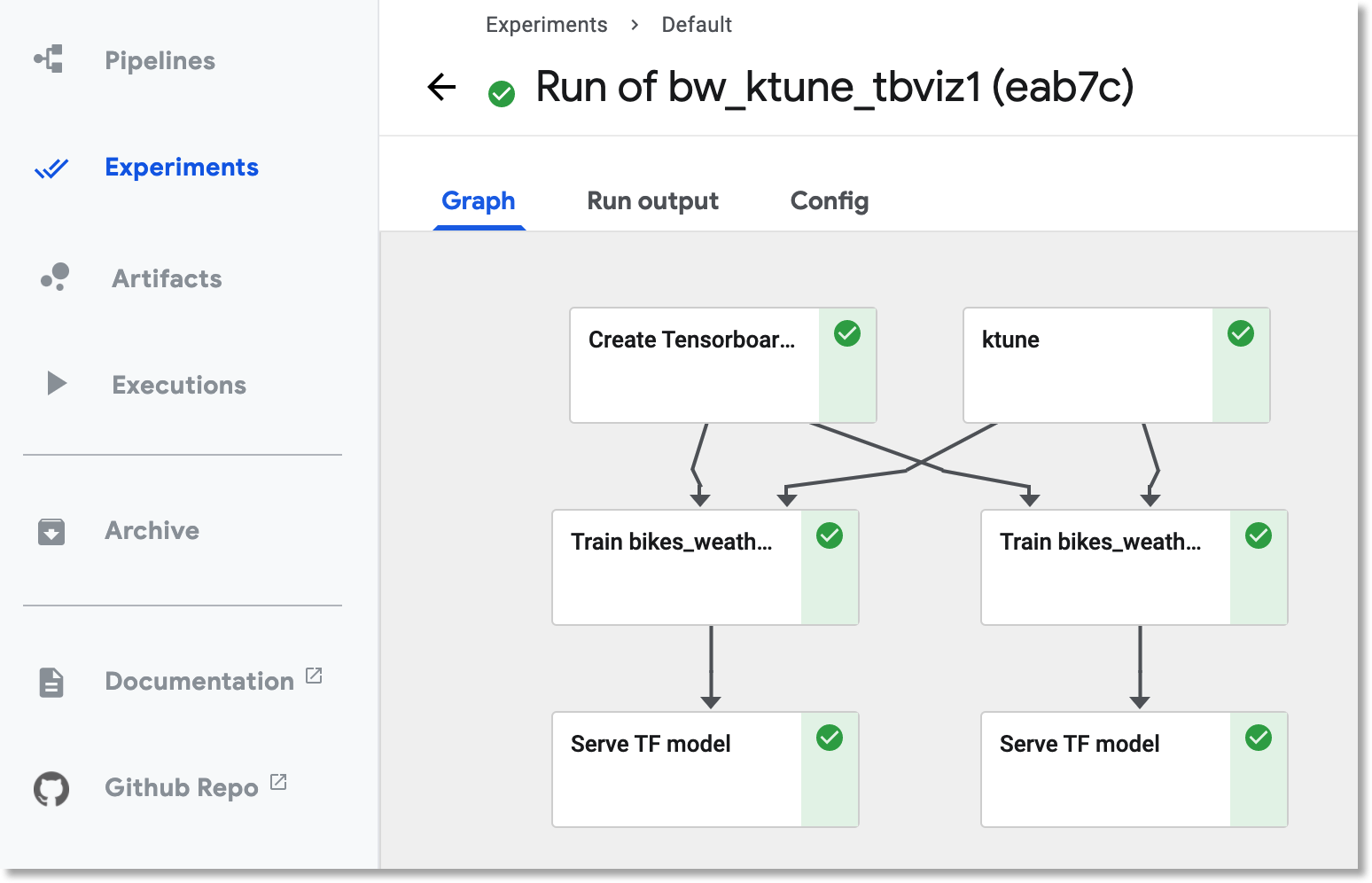
The DAG for keras tuner pipeline execution. Here the two best parameter configurations were used for full training.
Running the example pipeline
Note: this example may take a long time to run, and incur significant charges in its use of GPUs, depending upon how its parameters are configured.
To run the example yourself, and for more detail on the KFP pipeline’s components, see the example’s README.
What’s next?
One obvious next step in development of the workflow would be to add components that evaluate each full model after training, before determining whether to deploy it. One approach could be to use TensorFlow Model Analysis (TFMA). Stay tuned for some follow-on posts that explore how to do that using KFP. (Update: one such post is here).
While not covered in this example, it would alternatively have been straightforward to deploy and serve the trained model(s) using AI Platform Prediction.
Another alternative would be to use AI Platform Vizier for hyperparameter tuning search instead of the Keras Tuner libraries. Stay tuned for a post on that as well.