Using Google Cloud Functions to support event-based triggering of Cloud AI Platform Pipelines
This post shows how you can run a Cloud AI Platform Pipeline from a Google Cloud Function, providing a way for Pipeline runs to be triggered by events.




This example shows how you can run a Cloud AI Platform Pipeline from a Google Cloud Function, thus providing a way for Pipeline runs to be triggered by events (in the interim before this is supported by Pipelines itself).
In this example, the function is triggered by the addition of or update to a file in a Google Cloud Storage (GCS) bucket, but Cloud Functions can have other triggers too (including Pub/Sub-based triggers).
The example is Google Cloud Platform (GCP)-specific, and requires a Cloud AI Platform Pipelines installation using Pipelines version >= 0.4. To run this example as a notebook, click on one of the badges at the top of the page or see here.
(If you are instead interested in how to do this with a Kubeflow-based pipelines installation, see this notebook).
Setup
Create a Cloud AI Platform Pipelines installation
Follow the instructions in the documentation to create a Cloud AI Platform Pipelines installation.
Before executing the next cell, edit it to set the TRIGGER_BUCKET environment variable to a Google Cloud Storage bucket (create a bucket first if necessary). Do not include the gs:// prefix in the bucket name.
We'll deploy the GCF function so that it will trigger on new and updated files (blobs) in this bucket.
%env TRIGGER_BUCKET=REPLACE_WITH_YOUR_GCS_BUCKET_NAME
Give Cloud Function's service account the necessary access
First, make sure the Cloud Function API is enabled.
Cloud Functions uses the project's 'appspot' acccount for its service account. It will have the form:
PROJECT_ID@appspot.gserviceaccount.com. (This is also the project's App Engine service account).
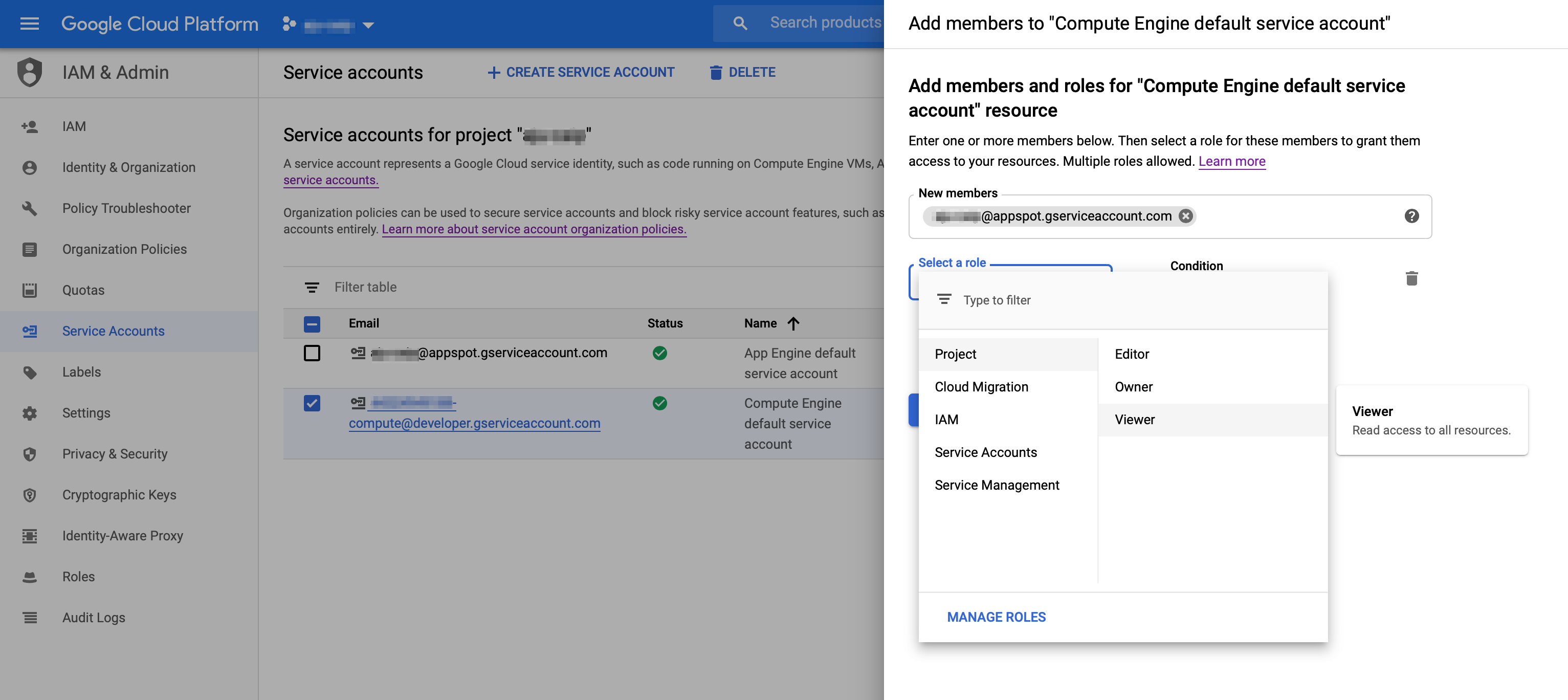
- Go to your project's IAM - Service Account page.
- Find the
PROJECT_ID@appspot.gserviceaccount.comaccount and copy its email address. - Find the project's Compute Engine (GCE) default service account (this is the default account used for the Pipelines installation). It will have a form like this:
PROJECT_NUMBER@developer.gserviceaccount.com. Click the checkbox next to the GCE service account, and in the 'INFO PANEL' to the right, click ADD MEMBER. Add the Functions service account (PROJECT_ID@appspot.gserviceaccount.com) as a Project Viewer of the GCE service account.
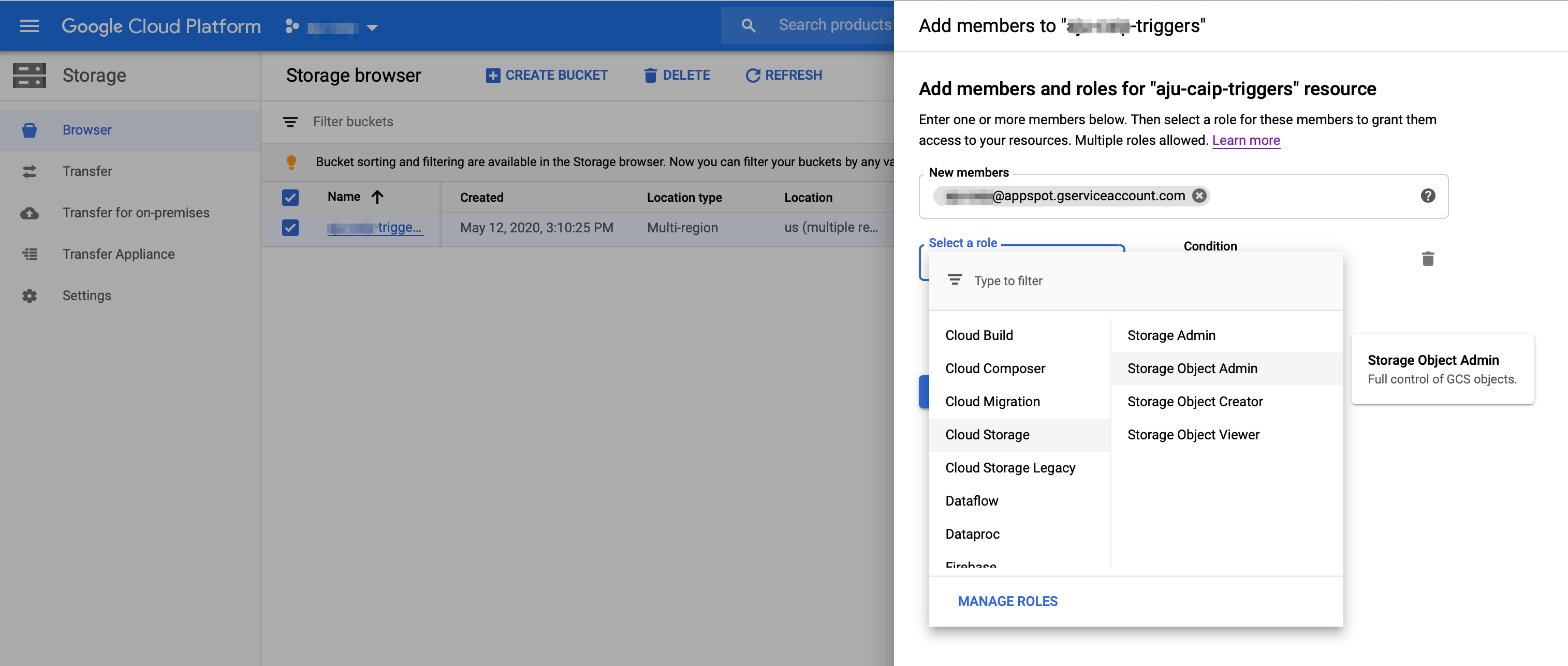
Next, configure your TRIGGER_BUCKET to allow the Functions service account access to that bucket.
- Navigate in the console to your list of buckets in the Storage Browser.
- Click the checkbox next to the
TRIGGER_BUCKET. In the 'INFO PANEL' to the right, click ADD MEMBER. Add the service account (PROJECT_ID@appspot.gserviceaccount.com) withStorage Object Adminpermissions. (While not tested, giving both Object view and create permissions should also suffice).
%%bash
mkdir -p functions
We'll first create a requirements.txt file, to indicate what packages the GCF code requires to be installed. (We won't actually need kfp for this first 'sanity check' version of a GCF function, but we'll need it below for the second function we'll create, that deploys a pipeline).
%%writefile functions/requirements.txt
kfp
Next, we'll create a simple GCF function in the functions/main.py file:
%%writefile functions/main.py
import logging
def gcs_test(data, context):
"""Background Cloud Function to be triggered by Cloud Storage.
This generic function logs relevant data when a file is changed.
Args:
data (dict): The Cloud Functions event payload.
context (google.cloud.functions.Context): Metadata of triggering event.
Returns:
None; the output is written to Stackdriver Logging
"""
logging.info('Event ID: {}'.format(context.event_id))
logging.info('Event type: {}'.format(context.event_type))
logging.info('Data: {}'.format(data))
logging.info('Bucket: {}'.format(data['bucket']))
logging.info('File: {}'.format(data['name']))
file_uri = 'gs://%s/%s' % (data['bucket'], data['name'])
logging.info('Using file uri: %s', file_uri)
logging.info('Metageneration: {}'.format(data['metageneration']))
logging.info('Created: {}'.format(data['timeCreated']))
logging.info('Updated: {}'.format(data['updated']))
Deploy the GCF function as follows. (You'll need to wait a moment or two for output of the deployment to display in the notebook). You can also run this command from a notebook terminal window in the functions subdirectory.
%%bash
cd functions
gcloud functions deploy gcs_test --runtime python37 --trigger-resource ${TRIGGER_BUCKET} --trigger-event google.storage.object.finalize
After you've deployed, test your deployment by adding a file to the specified TRIGGER_BUCKET. You can do this easily by visiting the Storage panel in the Cloud Console, clicking on the bucket in the list, and then clicking on Upload files in the bucket details view.
Then, check in the logs viewer panel (https://console.cloud.google.com/logs/viewer) to confirm that the GCF function was triggered and ran correctly. You can select 'Cloud Function' in the first pulldown menu to filter on just those log entries.
%%bash
cd functions
mv main.py main.py.bak
Then, before executing the next cell, edit the HOST variable in the code below. You'll replace <your_endpoint> with the correct value for your installation.
To find this URL, visit the Pipelines panel in the Cloud Console.
From here, you can find the URL by clicking on the SETTINGS link for the Pipelines installation you want to use, and copying the 'host' string displayed in the client example code (prepend https:// to that string in the code below).
You can alternately click on OPEN PIPELINES DASHBOARD for the Pipelines installation, and copy that URL, removing the /#/pipelines suffix.
%%writefile functions/main.py
import logging
import datetime
import logging
import time
import kfp
import kfp.compiler as compiler
import kfp.dsl as dsl
import requests
# TODO: replace with your Pipelines endpoint URL
HOST = 'https://<your_endpoint>.pipelines.googleusercontent.com'
@dsl.pipeline(
name='Sequential',
description='A pipeline with two sequential steps.'
)
def sequential_pipeline(filename='gs://ml-pipeline-playground/shakespeare1.txt'):
"""A pipeline with two sequential steps."""
op1 = dsl.ContainerOp(
name='filechange',
image='library/bash:4.4.23',
command=['sh', '-c'],
arguments=['echo "%s" > /tmp/results.txt' % filename],
file_outputs={'newfile': '/tmp/results.txt'})
op2 = dsl.ContainerOp(
name='echo',
image='library/bash:4.4.23',
command=['sh', '-c'],
arguments=['echo "%s"' % op1.outputs['newfile']]
)
def get_access_token():
url = 'http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/token'
r = requests.get(url, headers={'Metadata-Flavor': 'Google'})
r.raise_for_status()
access_token = r.json()['access_token']
return access_token
def hosted_kfp_test(data, context):
logging.info('Event ID: {}'.format(context.event_id))
logging.info('Event type: {}'.format(context.event_type))
logging.info('Data: {}'.format(data))
logging.info('Bucket: {}'.format(data['bucket']))
logging.info('File: {}'.format(data['name']))
file_uri = 'gs://%s/%s' % (data['bucket'], data['name'])
logging.info('Using file uri: %s', file_uri)
logging.info('Metageneration: {}'.format(data['metageneration']))
logging.info('Created: {}'.format(data['timeCreated']))
logging.info('Updated: {}'.format(data['updated']))
token = get_access_token()
logging.info('attempting to launch pipeline run.')
ts = int(datetime.datetime.utcnow().timestamp() * 100000)
client = kfp.Client(host=HOST, existing_token=token)
compiler.Compiler().compile(sequential_pipeline, '/tmp/sequential.tar.gz')
exp = client.create_experiment(name='gcstriggered') # this is a 'get or create' op
res = client.run_pipeline(exp.id, 'sequential_' + str(ts), '/tmp/sequential.tar.gz',
params={'filename': file_uri})
logging.info(res)
Next, deploy the new GCF function. As before, it will take a moment or two for the results of the deployment to display in the notebook.
%%bash
cd functions
gcloud functions deploy hosted_kfp_test --runtime python37 --trigger-resource ${TRIGGER_BUCKET} --trigger-event google.storage.object.finalize
Add another file to your TRIGGER_BUCKET. This time you should see both GCF functions triggered. The hosted_kfp_test function will deploy the pipeline. You'll be able to see it running at your Pipeline installation's endpoint, https://<your_endpoint>.pipelines.googleusercontent.com/#/pipelines, under the given Pipelines Experiment (gcstriggered as default).
Copyright 2020, Google, LLC. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.